Call Stack for Beginners - Part 1
Every process, no matter how it came into being, has at least one stack for the purpose of running itself. The programming language can be anything but it needs a stack to run. As usual is the custom we will write a c program to explain the concepts in a more detail. Before that we will have a basic understanding of why a stack is used and what’s its purpose (If you are really new to this world, then you should see what is stack first). Why stack?
Accomplishing a task with a computer program involves many steps, some steps can be repeatitive. This is the basis of the evolution of programming languages, functions. Functions can eliminate the repeatitive steps in your program. Assuming we never invented or know how to use stacks in computers, lets think about the program execution. The below will be missed out if we don’t have a stack.
- Lack of local variables, global variables are only available which then will make program more error prone.
- Real functions can’t exist, since a function has to return to its caller by storing return address.
- Threads can’t exist.
- Code size will increase, since functions will be just like macros (All functions have to be in-lined)
With such great advantages of a stack, all computers (microprocessors, microcontollers etc) have built-in support for stack.
The working of a stack
A stack is created when a process starts to run. The stack placement is based on
the operating system and architecture of the microprocessor. On a x86 machine,
the stack will be placed at the top of the address space of the process, and
then it grows down. The Linux kernel makes an anonymous mapping of a memory area
for the stack and sets VM flags with VM_GROWSDOWN. So on a page fault the
kernel maps more memory for the stack, which equals a PAGE_SIZE, starting from
the end of the stack (stack top). Theoretically stack can grow until there is no
more room in the memory. But usually the stack size is limited by the system
configuration.
$ ulimit -s # Maximum stack size of a program (soft limit)
8192
$ ulimit -Hs # hard limit
unlimited
When there is no limit we should ideally expect the program to be killed only when we run out of memory (OOM), but we have something called stack overflow too, which can occur even when enough physical memory is available. Stack overflow occurs when stack grows down and reaches the region where the next segment is present, which is the memory mapped area. So there is a hidden limit. To clarify lets see a rough layout of a process in memory. The next segment, which contains the memory maps for shared library etc. is placed after rlimit size with some offset. The following diagram can explain better.
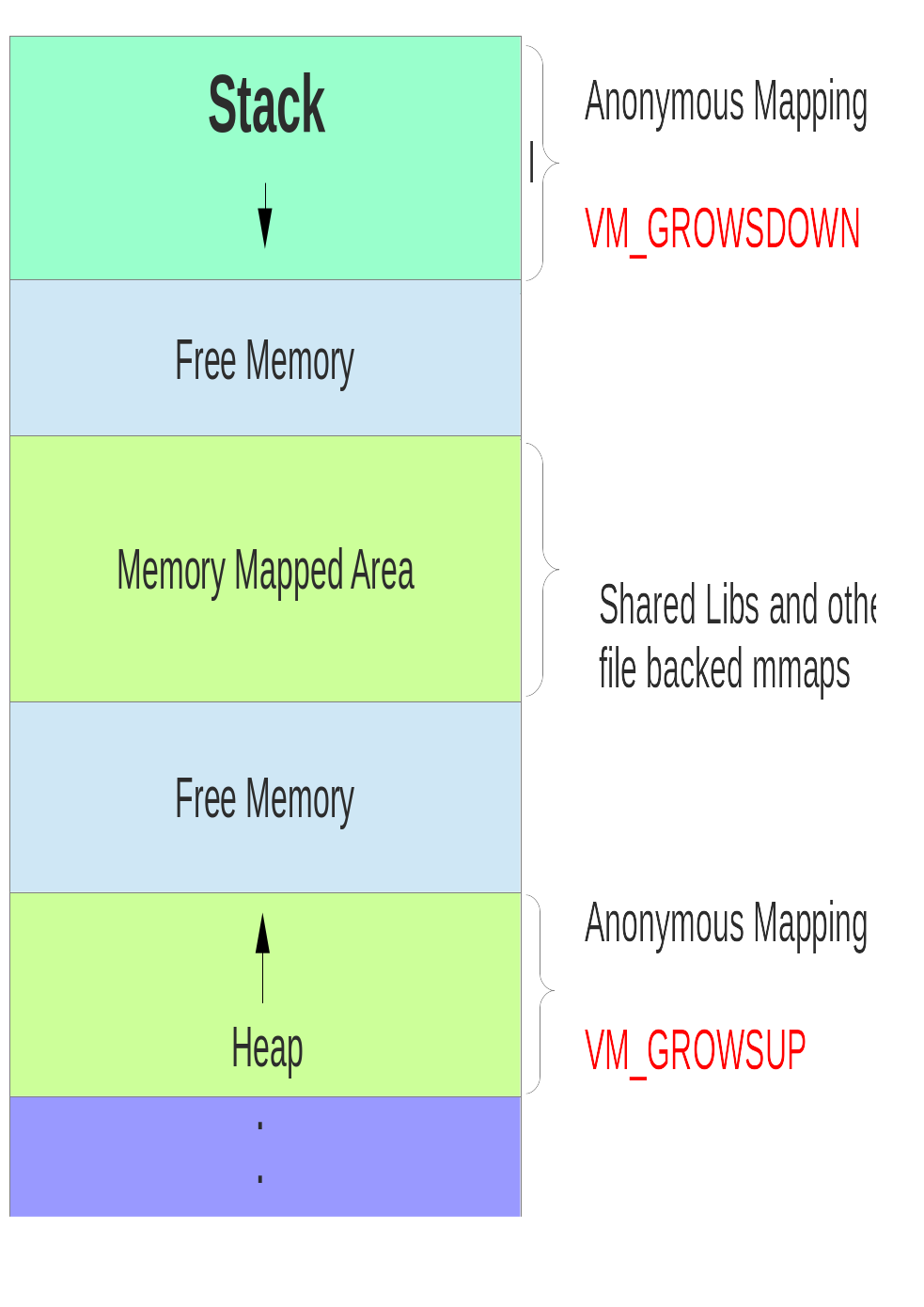
Does stack always grow downwards? Not for all architectures. At least in IA64 the stack grows up, so kind of the above diagram inverted.
Above the stack is the kernel space, and below the heap are the other sections
of the program, like the BSS, Data, Text (Code) etc. etc., which we will
take up in a later article.
Contents of a stack
Before getting into the details of what constitutes the stack, we will touch
upon the hardware support for stack. Most hardware have good support to make
stack usage very efficient. Usually a dedicated register is used to save the
address of the top of stack, called the stack pointer. Also instructions are
provided for pushing and popping elements in and out the stack. In x86 the stack
pointer register is called ESP1.
In C when each function is called a dedicated space for the function is created
in the stack, that’s called a stack frame. Those are like scratch-pads for the
functions, and this frame will be destroyed when the function returns. The frame
is also very important and very much used, which warrants for a dedicated
register. This is typically called the frame pointer FP and in some cases like
the x86 it’s called Base Pointer, and register name is EBP.
Let’s start with an example program.
#include <stdio.h>
int add(int a, int b)
{
int c;
c = a + b;
return c;
}
int main(int argc, char *argv[])
{
int a = 10, b = 1;
printf("%d\n", add(a, b));
return 0;
}
In the above example code, the first function to be called, as you should
already know, is main, which has a frame for itself. That frame holds all the
variables inside the function. These variables unlike global variables are not
even part of the final code generated, they are created during runtime and all
references of it are offsets from EBP, so a and b in function main will
be referred to as EBP - 4 and EBP - 8 respectively. In the below assembly
code of beginning of main, the variable creation can be found, but this case its
referred using offsets from ESP, but conceptually both are right.
movl %esp, %ebp
...
subl $32, %esp
movl $10, 28(%esp)
movl $1, 24(%esp)
Since EBP = ESP after mov %esp, %ebp, the new stack frame is created by
moving SP 32 bytes down, so now the next line of code mov $10, 28(%esp),
which means, move value 10 to address at ESP + 28, which also means EBP - 4. Let’s print addresses of SP and FP in both the functions and see what
else is we can discover. The following snippet shows how you can print the EBP
and ESP in a C program.
const unsigned int * register fp asm("ebp");
const unsigned int * register sp asm("esp");
printf("sp: %p fp: %p\n", sp, fp);
If you see clearly, printing all the addresses of the variables, the frame
pointer and the stack pointer of the main function, you will find that there are
some extra space in the stack, which is used for storing the return address and
the frame pointer of the current frame before calling add(). We will see in
detail about those in the next part of this article, where we will talk about
the x86_64 ABI, which is a little different from what we have seen here about
the 32 bit architecture (unfortunately there is no one size fits all solution).
*[OOM]: Out Of Memory *[BSS]: Block Started by Segment *[ABI]: Application Binary Interface
-
History of prefixing E can be found elsewhere. Hint: the move from 16 to 32 bit. ↩︎
Site design and logo and content © fossix.org